Prepare
- Before the post : https://jhs9396.github.io/2019-02-13-post9/
- This post is an example of using the levenshtein distance to create a relationship between data that is determined to be similar. I can not say that doing this is the right answer.
Scenario
- Suppose you have a sample of an cypher security report.
- Sample data is four reports (A, B, C, D report).
- Each report includes
- intrusion set
- ip
- domain
- hash
- file name
- purpose_info
1) Test data import
- Here same script : https://gist.github.com/jhs9396/115a0a047a2df098550cc4191d9bd69f
- Data copy & paste in CLI.
- If the data import is successful, you can see the following figure.
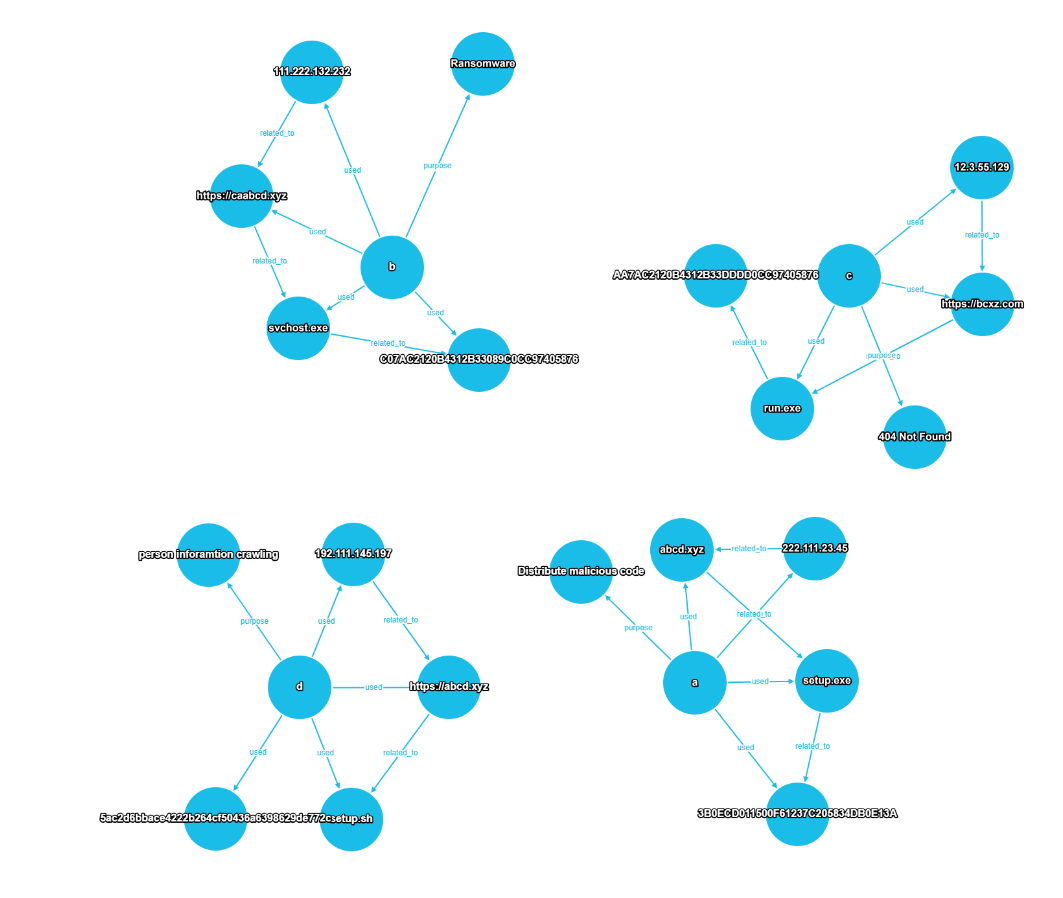
- It was used GraphUtilites for visualization. source is https://github.com/jhs9396/GraphUtilities
2) Levenshtein distance apply in graph model
- First, levenshtein distance result data store RDB Table.
- Set the value to be applied and execute the function.
- This post is based on the domain value.
- levenshtein function has two text arguments. One to be used for comparison, and the other to be compared.
- I used “abcd.xyz” for import test data.
- The domain value is a cypher query as follows.
MATCH (a:domain) RETURN a.value; - Create a hybrid query to include the query results in the table, and then create the table.
- to_string is a function for replacing double quotes. (User-Defined Function)
- to_string function example. https://jhs9396.github.io/2018-12-24-post4/
CREATE TABLE IF NOT EXISTS ls_result AS SELECT TEXT(g1.value) AS value , levenshtein('abcd.xyz', to_string(g1.value)) AS res FROM (MATCH (a:domain) RETURN a.value AS value) g1
- to_string function example. https://jhs9396.github.io/2018-12-24-post4/
- If you want to supplement levenshtein a bit more, you can create your own formula.
- example : 1-(levenshtein result)/(after two string compared, least length data)
1-FLOAT8(levenshtein('abcd.xyz', to_string(g1.value)))/FLOAT8(least(length('abcd.xyz'),length(to_string(g1.value)))) AS res - result data
agens=# SELECT * FROM ls_result; value | res ----------------------+----- "abcd.xyz" | 0 "https://caabcd.xyz" | 10 "https://bcxz.com" | 13 "https://abcd.xyz" | 8 (4 rows) - The closer to 0, the similar data.
- In a graph model, you can create edges of similar data. (by scheduler, crontab, etc)
- I will create an edge between data above a certain number. Before that, let’s look at the data using a hybrid query.
- With Graph path, MATCH execute. If pattern exists, data return. (result is used as an inline view.)
MATCH (a:ip)-[r]->(b:domain)-[r1]->(c:filename)-[r2]->(d:hash) RETURN a.value AS ip, b.value AS domain, c.value AS file, d.value AS hash - With RDB result table, JOIN executed. (Only the data whose result value is 8 or less is inquired.)
SELECT * FROM (MATCH (a:ip)-[r]->(b:domain)-[r1]->(c:filename)-[r2]->(d:hash) RETURN a.value AS ip, b.value AS domain, c.value AS file, d.value AS hash) g1 , (SELECT value FROM ls_result WHERE res <=8) t1 WHERE g1.domain::text = t1.value; ip | domain | file | hash | value -------------------+--------------------+-------------+--------------------------------------------+-------------------- "222.111.23.45" | "abcd.xyz" | "setup.exe" | "3B0ECD011500F61237C205834DB0E13A" | "abcd.xyz" "192.111.145.197" | "https://abcd.xyz" | "setup.sh" | "5ac2d6bbace4222b264cf50436a6398629de772c" | "https://abcd.xyz" (2 rows) - The results of levenshtein showed two similar values. If so, look directly at the data to see if they are related.
- Codes the script or logic to perform the following logic. I took an example just by copying and pasting.
MATCH (a)-[r]-(b)
WHERE a.value = '222.111.23.45'
AND b.value = '192.111.145.197'
RETURN *;
a | r | b
(0 rows)
MATCH (a)-[r]-(b)
WHERE a.value = 'abcd.xyz'
AND b.value = 'https://abcd.xyz'
RETURN *;
a | r | b
(0 rows)
MATCH (a)-[r]-(b)
WHERE a.value = 'setup.exe'
AND b.value = 'setup.sh'
RETURN *;
a | r | b
(0 rows)
MATCH (a)-[r]-(b)
WHERE a.value = '3B0ECD011500F61237C205834DB0E13A'
AND b.value = '5ac2d6bbace4222b264cf50436a6398629de772c'
RETURN *;
a | r | b
(0 rows)
- The assumption is made that these irrelevant data may be similar through the levenshtein function results, which may create relationships in the graph model.
- Creating edge module logic example.
MATCH (a:domain), (b:domain)
WHERE a.value = 'abcd.xyz'
AND b.value = 'https://abcd.xyz'
CREATE (a)-[r:similar_to]->(b);
- The result of creating the edge is as follows.
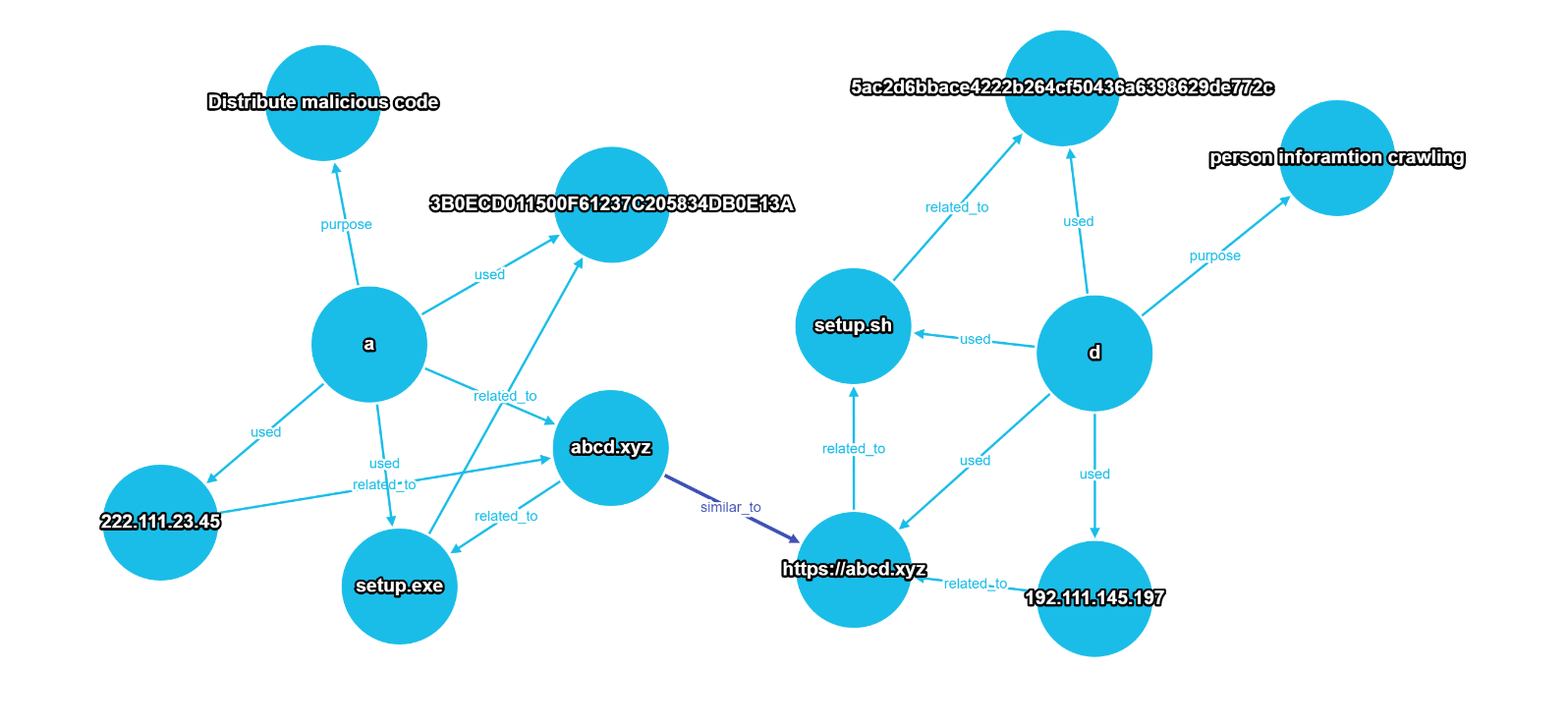
-
The standard for automatically generating edges is levenshtein.
-
A report and D report use different information, and originally there is no correlation, but it can be assumed that correlation can be created through this analysis.
-
The ip information used in the A report (222.111.23.45) may be the spoof, and the ip information used in the D report (192.111.145.197) may be the spoof.
-
Or The file (setup.exe) used in the A report may be related to the file (setup.sh) used in the D report, and the purpose_info (Distribute malicious code) of the A report and the purpose_info (person information crawling) of the D report There is an assumption that it may be relevant.
-
Creating an edge automatically implies that there is a relationship between data that was not originally related and data that is not related to each other in the graph model.
-
Of course, it is logical to assume that two values are similar with only one levenshtein.
- However, analysts always wanted to be able to construct formulas with a lot of assumptions, so I wanted to explain how I could infer these results by applying some analysis in the graph.